Roam Research 采用的是 Clojure 技术栈的 Datomic/datascript Datalog 数据库,能够将内容同步到不同的设备,并管理非常复杂的撤销操作,还能够支持各种程度的自定义组件和插件功能定制,方便开发者利用 Reagent 渲染组件,并支持与 JavaScript 互操作。本文就将硬核解析 Roam 背后原理,发掘 Roam 基于 Block 的深层技术优势,帮助你迎接 Roam API 时代的到来!
原文地址:A closer look at {roam/render} —— Zsolt Viczián

Roam 就好像一把优秀的瑞士军刀,竟然包含一个完整的 ClojureScript 开发环境。在过去两周里,我逐渐熟悉了 ` {{roam/render}} `。这篇文章可以算作我自己的笔记,总结整理一下我的所见所学。
这篇文章是针对开发者和 Roam 黑客的。如果你还不属于这些阵营,你很可能会对这些内容感到吃力。
我并不是一个 Web 开发者,React、Clojure、Reagent 和 Datalog 对我来说完全是崭新的事物。我是一个典型的无知者无畏的终端用户,我知道如何构建一个基于宏的庞然大物,但却无法保持其健壮/可测试/可维护。在玩roam/render的过程中,有一次我几乎把我的整个 roam 数据库都毁掉了 —— 这与roam/render无关,一切都是因为我太笨了。请谨慎尝试我的结论和例子,欢迎在评论中分享更好的解决方案,或者联系我进行勘误。
什么是 roam/render?
` {{roam/render}} `是Roam中用于构建自定义组件的原生特性。这些组件可以是简单的表格、计算器、滑块,也可以是复杂的交互式工具,比如数据透视表、图表、流程图等。
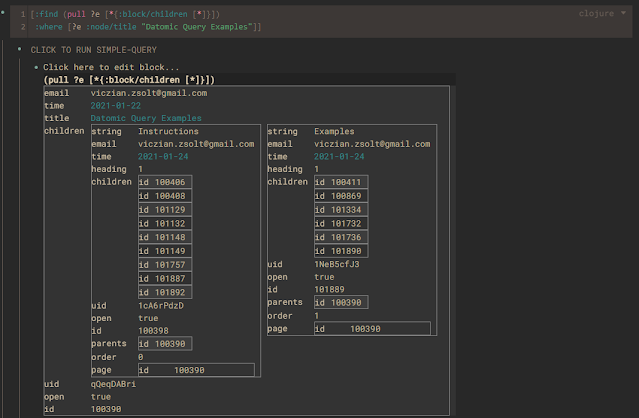
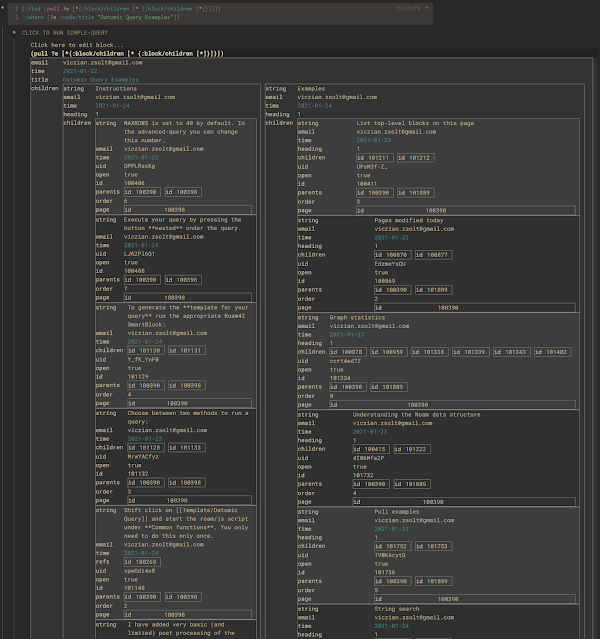
roam/render 也是一个使用 Reagent 在 ClojureScript 中实现的 React 组件。你可以使用 Datalog 在 Roam 的 Datomic Graph 中访问你的数据。
其实就在几周前,以上两句话中的每一个单词对我来说都是陌生的。让我们先来快速看看每个词的意思:
- React是一个用于构建用户界面的 JavaScript 库。*
- Clojure(/ˈkloʊʒər/, 很像 Closure 闭包的拼写)是一种支持动态类型和函数式编程的 Lisp 方言。和其他 Lisp 方言一样,Clojure 将代码视为数据,并有一个 Lisp 宏系统。*
- ClojureScript是一个针对 JavaScript 的Clojure编译器。*
- Reagent是一个 React 的 ClojureScript 封装。它可以帮助你轻松创建 React 组件。Reagent 有三个主要的功能,使其易于使用:使用函数创建React 组件,使用Hiccup 生成 HTML,以及在Reagent Atoms中存储状态。Reagent 可以让你写出简洁可读的 React 代码。*
- Hiccup是一个用于呈现 HTML 的 Clojure 库。它使用 vectors 来表示元素,使用 maps 来表示元素的属性。* 试着玩一玩HTML2Hiccup,可以帮助你更好地了解 hiccup 的工作原理。另外,你也可以直接在 Roam 中输入 hiccup,只要在一个空块中输入
:hiccup [:code "Hellow World!"],看看会发生什么。 - Atoms是 Clojure 中的一种数据类型,它提供了一种管理共享、同步、独立状态的方法。一个 Atom 就像其他编程语言中的任何引用类型一样。Atom 的主要用途是保存 Clojure 的不可变数据结构。 *
- Datomic是一种新型数据库。Datomic 不是将数据收集到表格和字段中,而是由Datoms
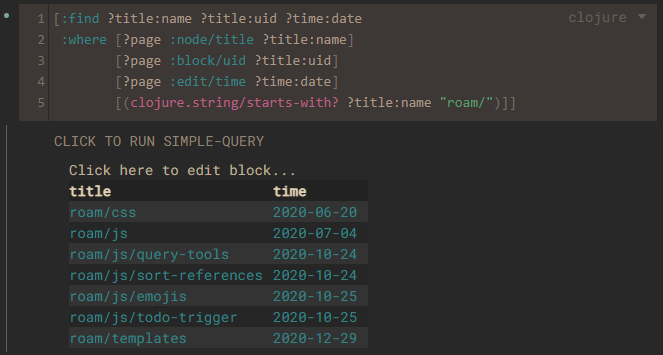
[entity-id attribute value transaction-id]建立。这种架构为改变和扩展数据库 Schema 提供了高度的灵活性,而不会影响现有的代码。* - Datalog是一种基于 Prolog 的声明式、基于形式逻辑的查询语言。*我分享了一些简单的 Datalog 实例,在这里查看如何生成 Roam Graph 有关的基本统计数据。
入门指南
开启自定义组件
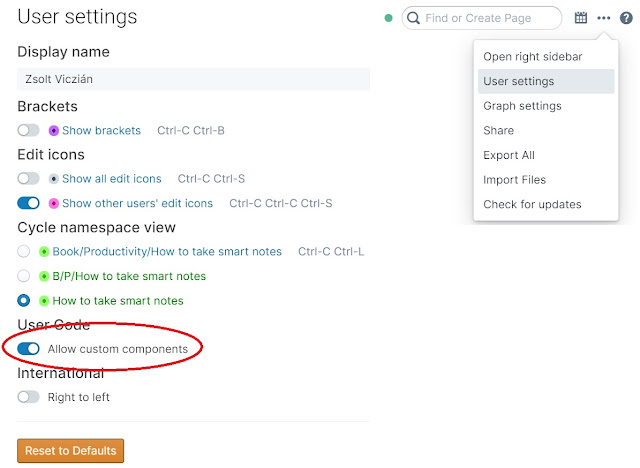
自定义组件功能默认是禁用的。在你搞事情之前,你必须在用户设置中启用它。
Hello World!
你可以通过在 Block 中添加以下代码来嵌入 roam/render: ` {{roam/render: ((block-ref))}} ` 其中 block-ref 指的是你的脚本代码的块引用。脚本代码必须至少有一个函数。如果这个 Block 有多个函数,那么在组件创建时只会调用最后一个函数。
被引用的代码块必须包含一个设置为 Clojure 类型的代码块。代码块的创建是通过使用三个反引号 ` ``` ` 来完成的。如果你不知道键盘上的反引号键在哪里,你也可以使用/菜单,然后选择 Clojure Code Block。

一步一步来
- 在一个新的 Block 中输入:
{{roam/render:((...))}}。 - 当你开始在双括号之间打字时,Roam 会弹出 “search for blocks”。选择 “Create as block below”。这将在你当前 Block 下面创建一个 Block,并自动在括号之间放置一个块引用。
- 导航到新的 Block,并添加两个额外的反引号``来创建一个代码块。
- 将代码的语言设置为 Clojure。
- 最好给每个组件都有自己的命名空间
(ns myns.1),虽然 Hello World 没有它也能工作。这将为你在以后的探索省去很多头疼的问题,因为当同名的函数相互竞争时,调试会让人非常头大。我遵循一个简单的模式,按顺序给我的测试命名空间编号。当我准备好了一个组件,我才会给它自己合适的命名空间。 - 代码块应该至少有一个函数:
(defn hello-world [])。 [:div"..."]hiccup 这种写法等价于<div>Hello World</div>。
(ns blogpost.1)
(defn hello-world []
[:div "Hello World"])
恭喜你!你已经使用 ClojureScript 成功创建了你的第一个 Roam 组件!现在你应该看到 Hello World 出现在代码上方的 Block 中。
接收 input 参数
当你开始为实际用例构建组件的时候,你很快就会意识到,如何知道当前组件正在运行的 Block 的 ID 呢?你需要这个 ID 来创建能够感知上下文的组件,即它们需要知道自己选择在哪个 Page 上,上级或上级有哪些 Block 等等。
我花了好几天的时间才发现如何做到这一点。我想让你省点力气! 当一个组件被调用时,Roam 会把 block-id 作为第 0 个参数传递给主函数(注意:你代码块中的最后一个函数)。当然,Roam 还会传递当你调用组件时,所输入的其他任何参数。
在新的 Block 输入下面的脚本,将产生以下输出。(当然,请注意,当你在自己的 Graph 中尝试这个脚本时,Block 的 ID ((Vy8uEQJiL))会有所不同,所以对应的 block-uid “eR7tRno7B “也会不同。)
{ { roam/render: ((Vy8uEQJiL)) 10 "input 1" ["input" "vector" "with" 5 "elements"] {:key1 "this is a map" "key2" "value 2" :key3 15} (1 2 3) #{"a" "b" "c"} } }

这里的内容很多。让我们借此机会学习一下 Clojure 数据结构。我正在向自定义组件传递六个参数。除了这六个参数之外,Roam 默认将 block-uid 作为第一个参数传递。如果你想深入了解 Clojure 数据结构,我推荐这篇文章。
- 第 0 个参数是
block-uid。它是作为一个单一元素的 map 传递的。 - 接下来,我添加到组件的第一个参数是一个 integer 整数。我可以简单地把它作为一个数字传递给组件。
- 然后是一个 string 字符串。Clojure 只接受双 “引号” 标记的字符串。单个 ‘引号’(单引号)有不同的含义。使用
'会产生一个不被计算的形态,下文还会提到如何在 datalog 查询中使用单引号。 - 第三个输入参数是一个 vector。请注意,在 Clojure 中,你可以用空格隔开一个 vector 的多个元素。这个 vector 总共有四个元素,三个字符串,一个整数。
- 接下来是一个有三个 keys-values 的 map。你可以使用 “string” 作为 key,就像在 JavaScript 对象中一样,然而,Clojure 还提供了使用
:keywords作为 key 的方式。关键词以:冒号开头。你可以使用,逗号来分隔 key-value 键值对,但这不是必须的。注意在输入中我没有使用逗号。 - 第五个参数(Arg 4)是一个 list 列表。列表的主要用途是表示未被计算的代码,在你进行元编程时,用来编写生成或操作其他代码的代码。
- 最后一个参数是一个 set 集合。set 和 vector 很像,关键的区别是 set 中的每个值都是唯一的。同样根据设计,set 中每一项的顺序是任意的。
代码本身是自解释的。你应该注意到我是如何使用[:b],相当于<b>...</b> 用来表示粗体文本。clojure.core/map-indexed将把输入向量 args 中的每个元素传给匿名函数fn[i n],其中i是索引号,n是正在处理的 vector 的当前元素。
(ns blogpost.2)
(defn main [ & args]
[:div
[:b "Number of arguments received: "] (count args)
(map-indexed (fn[i n] [:div [:b "Arg " i ": "] (str n) ]) args)])
现在我们知道第 0 个参数总是带有 block-uid 的 map,我们可以稍微修改一下我们的代码,将 block-uid 接收到一个专用变量中。这是我在所有组件中使用的 “standard” 主函数声明。 (defn main [{:keys [block-uid]} & args]。将前面的例子用标准 main 函数稍微改写一下,就会变成这样。
(ns blogpost.2)
(defn main [{:keys [block-uid]} & args]
[:div
[:b "The block-uid is: " ] (str block-uid) [:br]
[:b "Number of arguments received: "] (count args)
(map-indexed (fn[i n] [:div [:b "Arg " i ": "] (str n) ]) args)])
一个简单的 Reagent 表单
Reagent 是表单交互的关键。它们允许你根据用户输入的数据,动态地改变组件的 HTML 渲染,无论是组件本身还是在 Graph 中的 Page 页面。
为了理解下一个例子,你首先需要了解 Clojure 变量。Clojure 中的所有变量都是不可变的,这意味着它们是作为常量创建的。变量可以有不同的作用域,也就是说,你可以在命名空间的层次上定义变量,或者只是在一个函数中定义变量。但是一旦设置,它们的值就不能改变。
有几个方法可以绕过这种不可变性。其中之一是通过使用 atoms。 atom 的工作原理我就不深究了(顺便说一句,就算我想解释也解释不清楚),Atom 就是对一个值的引用。使用 swap! reset!可以把这个引用改成一个新的值。在clojure.core/swap!中,你可以在给 Atom 分配新的值之前访问它的前一个值,在clojure.core/reset!中,你只需给 Atom 分配一个新的值,而不用去管它的前一个值。
在roam/render中,我使用reagent.core/atom而不是clojure.core/atom。Reagent atoms 与普通 atoms 完全一样,只是它们会跟踪derefs(即访问它们的值)。Reagent 组件如果 derefs(解引用)发现其中的值发生变化,就会自动重新渲染。在实践中,这就意味着你可以根据数据的变化动态地改变组件。
我们将构建一个简单的表单,只包含一个输入字段。当你在 Graph 中输入一个页面的名称时,这个表单就会返回该页面的 UID。例如,你可以用这个来创建一个直接超链接到你的页面,URL 格式为 https://roamresearch.com/#/app/YOUR-GRAPH/page/9char-UID。
(ns blogpost.3
(:require
[reagent.core :as r]
[roam.datascript :as rd]))
(defn query-list [x]
(rd/q '[:find ?uid .
:in $ ?title
:where [?e :node/title ?title]
[?e :block/uid ?uid]]
x ))
(defn main []
(let [x (r/atom "TODO")]
(fn []
[:div
[:input {:value @x
:on-change (fn [e] (reset! x (.. e -target -value)))}]
[:br]
(query-list @x)])))
有几件事值得解释一下:
- 请注意命名空间声明下的
:require块。这些是我们代码中引用的命名空间。我稍后会分享一个简单的组件,你可以用它来探索 Roam 中所有可用的命名空间。使用:as你可以指定一个别名来引用你代码中的命名空间。 - 在
query-list函数中,我们使用roam.datascript(rd) 命名空间中的q函数执行一个简单的数据记录 query。请注意查询'[:find ?uid .开头的单引号'。另外,请注意?uid后面的点.。这个点.将查询的结果转换为一个标量。我在这里使用它,是因为我想要找一个单一的 uid 值作为函数返回值。 - 依然是
query-list函数,请注意我们没有在函数的结尾有一个类似于 JavaScript 的return的语句。在 Clojure 中,函数中最后一次调用的结果总是被返回。由于query-list只包含一次调用,所以在执行 query 时,将直接返回rd/q的结果。 - 请注意,在
main函数中,x被定义为一个初始值为 “TODO” 的 Reagent atom。将声明放在(fn[]后面的匿名函数之外,可以确保在创建组件时,只会设置一次 atom,而不是在每一次往 INPUT 框输入任何文本时,都将其重置为默认值。
以上是由Conor的一个例子改编的。你可以在 Roam help 数据库 这里 找到 Conor 的版本。我的解决方案和 Conor 的解决方案之间的一个关键区别是,他使用的是roam.datascript.reactive,而不是仅仅使用roam.datascript。在这个具体的例子中,从我的理解来看它们是没有区别。如果我的理解是正确的,Datascript reactive 提供了一种创建查询的方法,当其结果集发生变化时,它可以自动识别。它们可以用于创建交互式组件,比如 {{table}} 。
如何存储组件的属性值
当你重新打开页面或关闭并重新打开 Roam 时,组件会被重新初始化。在大多数情况下,你会希望以某种方式存储组件的属性,这样当你下次打开页面时,你会发现组件处于你离开时的状态。
你可以选择将信息写入 Block 中,并决定写入哪一个 Block。你可以写到嵌套在组件下的 Block ,或者写到一个工具页面上的 Block 里面,例如[[my component/data]] 或者更新执行组件的那个 Block。最后一种选择涉及更新 {{roam/render: ((block-UID)) }} 与 input 参数,这与我们在前面的例子中打印 input 参数的方式有些类似。我将在一个非常简单的例子中演示如何做到这一点。
顺便说一下,我用datascript.core做了一个实验,将自定义实体写入到 Roam 数据库。我也能够执行查询,但是没有找到一种方法让 Roam 保存更改。手动编辑自定义实体到 EDN 文件中是可行的(演示),所以使用datascript添加自定义实体应该也是可行的。
(ns blogpost.4
(:require
[roam.datascript :as rd]
[roam.block :as block]
[clojure.string :as str]))
(defn save [block-uid & args]
(let [code-ref (->> (rd/q '[:find ?string .
:in $ ?uid
:where [?b :block/uid ?uid]
[?b :block/string ?string]]
block-uid)
(str)
(re-find #"\({2}.{9}\){2}"))
args-str (str/join " " args)
render-string (str/join ["{{roam/render: " code-ref " " args-str "}}"])]
(block/update
{:block {:uid block-uid
:string render-string}})))
(defn main [{:keys [block-uid]} & args]
(let [some-value [1 2 "string" {:map "value"}]]
[:div [:strong "args: "] (str/join " " args) [:br]
[:button
{:draggable true
:on-click (fn [e] (save block-uid some-value))}
"Save"]]))
这个组件将保存 some-value 的值。在这个例子中,为了简单起见,它是硬编码的,但当然,你可以构建任何你想要的数据结构来代替 some-value。请注意以下几点:
- 我的
save函数是在 main 函数中按钮的:on-click事件中调用的。在我的实验中,每次组件改变其值时自动调用 save 的效果并不好,因为每次覆盖{{roam/render: ((block-UID))}}的时候,组件都会重新初始化,使得无法填写表单,或者通过交互的方式使用组件。 - 我在
save函数中定义了三个变量。code-ref、arg-str和render-string。 code-ref将保存block-string的当前值,因为我在执行 datalog 查询的时候,会读取:block/string属性的当前值,并通过block-uid过滤。->>是一个函数,它通过一组(str)和(re-find)的形式来执行表达式。它的唯一目的是让代码更易读。re-find中的正则表达式会找到{{roam/render:后面的((block-UID))。- 一旦
render-string准备好了,我就调用roamAlphaAPI的block/update将 Block 更新为我的 string 文本。
下面是这段代码的运行情况:
似乎还有一种方法,可以使用 Reagent 在 Form-3 Components 中所提供的:component-will-unmount事件处理器,来触发保存组件。虽然我还没有尝试过这种方法,但根据文档,这应该提供了一种方法来存储组件的属性,当你导航到不同的页面时,它就会从当前视图中消失。如果你对此感兴趣,你可以阅读这里。
如何与 Javascript 互操作
ClojureScript 提供了一种调用 JavaScript 函数的简单方法。当你想访问 DOM document 属性或函数时,这就非常实用了。比如调用 roam42 函数或创建一个 JavaScript 钩子来处理roam/render组件的数据(可以节省你学习 Clojure 的时间)。
第一个例子是返回页面的 location 位置。
(ns blogpost.5)
(defn main []
[:div (. (. js/document -location) -href)])
请注意 JavaScript DOM document 是如何使用js/document访问的。
属性是用-property符号来访问的。用于访问对象属性的 JavaScript . 点符号,需要转化为嵌套的小括号,每个括号都调用下一个属性或函数。
使用->可以使代码更易读,特别是在属性链特别长的时候。
(ns blogpost.6)
(defn main []
[:div (-> js/document
(.-location)
(.-href))])
现在,我们将再做一遍上面的 Reagent 表单简单示例 (blogpost.3),但是将(defn query-list [x]替换为 JavaScript 来执行我们的 datalog 查询。

下面是 ClojureScript 的代码。
(ns blogpost.7
(:require
[reagent.core :as r]))
(defn main []
(let [x (r/atom "TODO")]
(fn []
[:div
[:input {:value @x
:on-change (fn [e] (reset! x (.. e -target -value)))}]
[:br]
(.myDemoFunction js/window @x)])))
以及 ` {{roam/js}} ` 的代码。
window['myDemoFunction'] = function (x) {
return roamAlphaAPI.q(`[:find ?uid .
:in $ ?title
:where [?e :node/title ?title]
[?e :block/uid ?uid]]`, x);
}
如果你想把多个变量传给 JavaScript,你可以在函数调用(.myFunction js/window variable-1, @an-atom, block-uid)之后简单地列出这些变量。
Roam 已有的命名空间
在 roam/render 中有以下命名空间。
- Clojure: cljs.pprint, clojure.core, clojure.edn, clojure.pprint, clojure.repl, clojure.set, clojure.string, clojure.template, clojure.walk。
- Roam: roam.block, roam.datascript, roam.datascript.reactive, roam.page, roam.right-sidebar, roam.user, roam.util。
- 其他: datascript.core、reagent.core。
这段代码将列出每个命名空间中所有可用的函数。
(ns blogpost.8)
(defn main []
[:div (map (fn [x] [:div
[:strong (pr-str x)]
[:div (map
(fn [n] [:div (pr-str n)])
(->> (ns-publics x)
(seq)
(sort)))]])
(into [] (->> (all-ns)(map ns-name)(sort))))])
Tips 和技巧
一些有用的链接
- A community coding style guide for the Clojure programming language
- Clojure - Cheatsheet
- Community-Powered Clojure Documentation and Examples
- A visual overview of the similarities and differences between ClojureScript and JavaScript
- My blogpost on Roam Datalog
- Datomic Queries and Rules
- datascript.core - datascript 1.0.4
- ClojureScript + Reagent Tutorial with Code Examples
- Clojure Data Structures Tutorial with Code Examples
- My growing list of roam/render examples in the Roam help database
- Clojurescript Interop With Javascript
- Getting Work Done in Clojure: The Building Blocks
- HTML2Hiccup - An HTML to Hiccup converter for Clojure and ClojureScript
下面是我自己写的一些组件,因为我在继续深入研究roam/render。请在你的测试/开发 Graph 中尝试它,一定要格外小心。虽然我相信这些例子,应该可以在不损坏你的数据库的前提下工作,但如果出了问题,我概不负责哦……
- A configurable roam/render form with a javascript hook
- An alternative table component
- A query component for free text sibling query
你也可以随意浏览我的 Graph,里面有很多有关 Clojure 和 Reagent 成功和不成功的尝试。我会尽量把成功/不成功的解决方案都标出来。
调用组件
` {{roam/render: ((block-UID))}} 引用组件的形式不是很友好。它需要点击几次才能得到 block-uid` 并将其插入到渲染的 Block 中。我发现了两种选择。
你可以在 roam/templates 中创建一个简单的本地漫游模板,然后在那里用一个友好的名字添加你的组件。然后,当你需要它时,你可以使用;;template-name将组件插入到你的文档中。
你也可以 Hack 一下 block 的 UIDs。我在这里提供了一个解决方案。这将允许你用更友好的名字来创建组件,比如我的 query 查询组件。 ` {{roam/render: ((str_query))}} `。
前置声明
这个让我头疼了几个小时。 Clojure 采用的是单通道(single-pass)编译。这意味着,如果一个函数在声明之前被调用,编译器会抛出一个错误。在某些情况下,不可能按照函数的使用顺序来声明函数,比如在涉及两个函数的迭代中。这时clojure.core/declare就很用了,你可以做一个正向声明,编译器就会知道,在这之后会有这个函数的定义。
输出 Roam 的原生链接
如果你正在构建组件,当你想输出 Roam 原生链接时将会遇到一个问题。你可以直接点击链接,就会打开页面。你也可以shift-click的链接,就会在侧边栏中打开页面。我发现有三种方法可以实现输出这种可工作的链接。
最简单的方法是使用roamAlphaAPI创建一个 Block,并在这个 Block 字符串中放置一个page link或block-ref。这将转换为一个正确的 Roam 链接。
另一种方法是创建一个包含 Roam 查询的 Block,并在查询参数中包含你想显示的链接: {{query: {or: page linkblock-ref}} 。
由于 Roam 在几天前发布了roam.right-sidebar命名空间,现在可以完全模仿 Roam 原生链接了。我还没有时间去试验这第三个选项,但它看起来是可行的。
如果你对此感兴趣,不妨到我的Graph中看看,也许从写这篇文章的时候起,我已经实现了解决方案。 我将创建一个响应点击事件的 Reagent 组件。在点击时,我将把浏览器导航到一个类似于下面 JavaScript 例子的链接。在shift-click时,我将使用roam.right-sidebar来打开链接。
function getRoamLink(uid) {
if (window.location.href.includes('/page/'))
return window.location.href.substring(window.location.origin.length + 1, window.location.href.length - 9) + uid
else
return (
window.location.href.substring(window.location.origin.length + 1, window.location.href.length) + '/page/' + uid
)
}
Debug 调试
我使用的是以下代码进行调试。通过将 slient 开关转为 true,我可以禁用console.log调试信息。可能无需多言,input 参数只是为了这个例子。

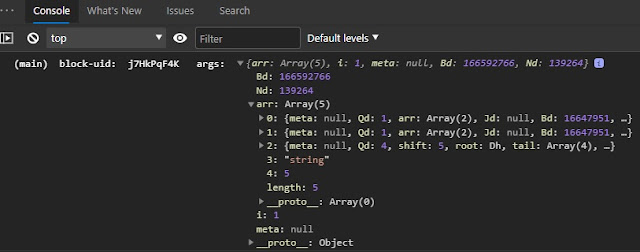
(ns blogpost.9)
(def silent false)
(defn debug [x]
(if-not silent (apply (.-log js/console) x)))
(defn main [{:keys [block-uid]} & args]
(debug ["(main) block-uid: " block-uid " args: " args])
[:div "debug demo"])
一些限制
基于 Roam 是一个笔记应用这个前提,拥有 ClojureScript 环境当然很牛逼。但是,就像瑞士军刀的微型锯子一样,在某些情况下,它是很方便的。但如果你想砍一棵树,请去买一把电锯。
roam/render 有两个巨大的限制。它没有文档,更重要的是,它缺乏适当的调试工具。它确实会将一些错误信息输出到控制台日志中,如果有一致的调试信息,就有可能追踪到错误,但它严重缺乏基本的调试功能,如 breakpoints、watches 等等。当你排除 ClojureScript 代码故障时,就会比本来要花费的时间要长很多。
比较好的一点是,你可以将代码分别放到兄弟层级的 Block,这样就可以更好地添加注释了,利用中间的 Block 加入流程图、解释等,有点类似于 Python 中的 Jupiter Notebook。但是,你无法将可能频繁使用的函数,放到同一个共享的命名空间,以便在组件之间重用。我尝试将引用共享名称空间的 Block 作为组件的同级 Block,但不起作用。一个变通的办法是把所有组件的源代码放在同一个页面上,并放到同一个命名空间中。这样做是可行的,但如果你有很多组件,恐怕会变得很乱。这也会让你很难跟其他人共享组件。
Datascript 也有一些限制。你不能创建自己的转换函数。你不能在 Roam 数据库中创建自定义实体。还有一些 Clojure 命名空间和函数缺失。例如,clojure.string/lower-case无法使用。我想使用小写字母来支持对大小写不敏感的搜索,幸运的是,实际情况下配合 clojure.core/re-find与clojure.core/re-pattern 的 (?i) flag 有一个可以变通的方法。
最终结论
在笔记应用中拥有一个 Clojure 执行环境绝对是很酷的。但是,如果没有相应的调试工具和文档,开发组件的效率其实非常低。
比较好的一点是 roam/render 和 ClojureScript 可以用来输出渲染自定义组件,比如表单、数据透视表和其他交互工具。
基于我现有的知识,其实与 JavaScript 互操作似乎是最好的方式。你可以使用 roam/render,顾名思义,渲染输出的部分,然后你可以使用 JavaScript 来构建应用程序的逻辑部分。如果这样做的话,你就可以同时得到两个世界里最棒的部分了。你可以在 Reagent 中轻松地渲染响应式组件,这样就是在一个真正的开发环境中,使用满足需求的调试工具完成大部分的开发工作。此外,你可以使用你已经熟悉的语言进行开发(假设你已经具备了 JS 技能),你还能够在 JavaScript 中创建可重用的代码,这样还可以跟其他人共享复用代码。