这里面其实暗合了 OKRs 的思路。只有当我将人生、年月季度的 Objective 自上而下拆分到每一天的执行,然后自下而上的输入(Roam Research 过程笔记),才是有可能真正去实现目标。我需要思考的如何去执行目标之下的任务,而且更应该思考如何更好地完成目标而非任务本身。
Roam Research 最棒的大纲和Sidebar侧边栏展开
任务的“执行”交由 AI
围绕目标之后的输入 Input 和输出 Output,让我收获了更有价值的成就感。但大语言模型的到来,破坏了这种获得感,LLM 天生擅长于“文字游戏”,AIGC 内容生成在输出端以降维打击之势碾压了人类。在频繁使用 ChatGPT 等 AI 工具之后,不自觉会把人类的弱点跟 AI 的优点对比,直面人本身的弱点的同时,还需要直面 AI 本身强于人的优点。这个过程那是真的难受,于是真正“作为人”的写作需要另外的工具。
大纲的价值在于层次结构的力量,也就是将主题和子主题层层分解,有助于将信息分成可管理的部分。并且在 Roam Research 这类软件当中,可以非常自由调整父子主题的位置,即指代了层级和同级的关系,并且还能轻松合并同类项。Roam Research 还可以同层级展开或折叠节点,在深入某个局部的同时,保持对整体结构的鸟瞰。
Gingko 跟 Roam Research 比还差一个 card ref,如果也能直接“穿针引线”的话,那简直就是绝,但我觉得可以互为补充。Roam Research 强于记录,但是写作输出则是另外一条逻辑,Roam Research 反而过于发散而无法专注。写作应该化网状为线性,根据 Gingko 作者的初心(写论文),我觉得 Gingko 在系统性输出上会更友好。
Roam Research 的灵活度与发散主要体现在 block ref(块引用),block embed(块嵌入)用得飞起,结果就是上下文插入过多,主线就不够清晰了,大纲 Outliner 这种其实也不适合项目或任务管理,甚至也不适合写作(成品输出),我现在也很少 all in one 甚至杜绝 all in one Roam Research。或者说,已经断了执念all in one 任意一款软件啦,哈哈哈
群友 @赣中 在讨论很多 APP 的功能视图都能在 Roam Research 实现,包括 Timestripe和 Gingko,我之前做的「Roam卡片式主题」灵感就来自于 Gingko;但是 Roam 不固化 Pattern,终端用户是没法用的。就像你要开发个应用,你把字段设计好了,存 DB 数据库里了,然后你跟用户说你会写 SQL 吧,你自己查吧,应用层面的 UI 咱就不做了。
其实对于工具的选择还是因人而异,Roam Research 的根基 pattern 就是 outliner,这是我用得最顺手的 pattern(模式),也许跟每个人的大脑偏好有关:
有些人的pattern可能是folder,
有些人的pattern可能是tags,
有些人的pattern可能是mindmap,
更高阶的,
有些人的pattern可能是TheBrain的父子兄
有些人的pattern可能是Excalidraw自由白板
有些人的pattern可能是纸笔,自带边界限制
Heptabase 原名 Project Meta,就是你所说的定义好字段,然后推出一堆的 Meta Apps(现在官方也有3、4个咯),本质上就是结构化数据之上的pattern,即应用。
以“人”为本,实践出“喜欢”
如果要说“最”喜欢的某种 pattern,那其实就只能选一种,但凡宣称所有 pattern 都支持的,可以灵活供选择的都是骗子。或者说,在最合适的场景下,应该选择最合适的 pattern 吧!或者换个角度来说,“人”相较于 AI 所能探寻的情绪价值是更重要的,“喜欢”本身就需要实践和时间。越用越喜欢的工具,哪怕忍受它的各种问题,一定是因为它那 20% 最特别的地方吸引了最独特品味的你。
而 Tana 则是新的搅局者,第二大脑的作者 Tiago Forte 称之为 "the new Roam",而社区更倾向于将其描述为 Notion + Roam Research 的孩子。Tana 的早期起势非常高调,社区大 V 们纷纷高潮,奔走相告,再加上邀请制一码难求,期待值非常高,堪比 Arc 浏览器。
New Bing 弥补了 GPT-3 缺失实时网络搜索结果的缺憾,聚合总结的效果更加震撼。并且,Edge 浏览器中的 New Bing 能够直接与网页的内容直接进行交互,让 ChatGPT 根据用户实时浏览的内容进行智能问答。众所众知,浏览器作为互联网的入口,所浏览的内容不局限于网页,同样可以作用于 PDF、图片等其他内容,因此想象空间更为巨大。
由此,微软所打出的 New Bing 搜索引擎 + New Edge 浏览器,让这两个领域都占据先手优势的谷歌猝不及防,已有的 Google 搜索和 Google Chrome,不得不开始跟上脚步和踩准节拍。好玩的是,谷歌联合创始人拉里·佩奇(Larry Page)和谢尔盖·布林(Sergey Brin)都被紧急召回,更频繁地参与到公司业务当中,布林甚至亲自下场为谷歌聊天机器人Bard写代码。然而被给予厚望的先发产品 Bard,还是在发布会演示时就立马栽了跟头。
另外,去年我的 B 站关注数突破了5000,总计发布83个视频,累计时长22小时,而这背后所花费的录制和剪辑的时间至少是10倍以上啦。令人唏嘘的是,近一年的 B 站总收益是668.33元,不足少数派的一篇稿费,🤣 这更加鼓励我要继续努力。所以,非常感谢看我的文章和视频的各位,也特别感谢2022年新关注的4334位小伙伴,希望你可以和我一起,用努力来获得幸运,迎接新的一年!
重点来了,阅读时,我还会打开「学习模式」的 Title Link(标题字典),并且在文档中打开 Recall Mode(回顾模式),从而在阅读的过程中,就开始回想所提取的新概念。
高亮之后,打开大纲模式,选择 Emphasize(强调),并且选中强调会同步到标题。此时,点击「正交性」这个词,它会自动同步到卡片标题上。而所有文中出现「正交性」这个关键词的地方,都会有一个小小的下划线。点击它,在左边的大纲中,就会出现词的具体解释,而在右边 PDF 的划线高亮段落中,所有关于「正交性」的词语都会隐藏起来,让你通过回想强化一次「提取强度」。
进入正文之前,我先稍微偏个题,本文的大纲是结合了 L 先生的几个有效的方法,共同构成的。那么这份大纲是如何在 Roam Research 中产生的呢?推荐给你一个好用的方法 —— 我在思考某个话题,或者是看一本书之前,会带着自己的问题(比如,如何克服精神内耗?)首先写下自己的想法,再去看你要读的材料。
比方说当时我就写下了自己的四个想法:使用 Roam Research 写下来、尽快进入下一阶段、冥想、任务驱动。然后呢,我再去读 L 先生关于有效克服精神内耗的方法,我相应地再去做阅读笔记,将文章里面提到的四个方法,跟之前自己所写下的四个角度进行对比。
你会发现大差不差的,我自己想的 4 个方法竟然跟 L 先生提出的 4 个方法是非常类似的,只是它们的顺序有所不同。从而,我就进一步通过 block reference 将它们关联了起来,相当于打通了自己的知识跟学到的知识的关联。
Unsplash: woman sitting on cliff overlooking mountains during daytime
注意,这跟发呆还不太一样,严格意义上来说,发呆并不算冥想,也不等同于冥想。其实,我对冥想粗浅的理解就是 yes and let it go(确认,然后就让它随风而去)。冥想最初源自佛教,而正念是 1979 年由巴卡金博士把这种修习的方式从宗教属性里面剥离出来的。从而,正念指的就是有意识的觉察,专注于当下这一刻,而不附加任何主观的评判。正念摆脱了宗教的性质,结合一些医学研究才提出了 Mindfulness 觉知的概念。
所以说,现在就动起手来,直接通过 Tab + Enter 的方式在 Roam Research 里面进行细化分解,而这种大纲式的组织结构会成为你的有力助手。大纲的树状结构可以让你不断地放大缩小,就像我经常提到的,Roam Research 就像有焦距的镜头,有微距也有广角,可以看到整棵树的全局或细节。
对了,这篇文章同样是遵循了「先录视频,再写文章」的知识输出工作流。我在录制视频发布 B 站 之后,会通过飞书妙记的语音识别自动化生成文章初稿,再配合我记录下来的大纲进行初步修改。至此,文章基本的结构已经成型,我只需要再去补充跟它有关的一些内容和插图,插图可以直接来自我视频的截图,就能非常快速地产出这篇文章啦。
在 Ted Nelson 构想的超文本系统中,我们访问的所有的网页或者叫文本,都应该是相互链接的。Xanadu(上都)是一个拥有很富文学意涵的字,马可·波罗(Marco Polo)在他的自传里提到 Shan-Du,指的是忽必烈汗元帝国的夏季之都。1965 年,Ted Nelson 将他发起的超文字构想,依照柯立芝的诗命名为「仙那度计划」(Project Xanadu),因为他认为仙那度是「一个记忆永远不会被遗忘的神奇地方」。
前文提到我自己的兴趣点,关注知识管理已经很长时间了,而 Roam Research 提供的双向链接刚好解答了我探索已久的困惑。与此同时,在中文社区,特别是对于我自己而言,我也在寻找很多的一些同路者,大家一起来学习探讨新的工具,一个极具突破性的工具。所以,我就不断地在使用这款工具来管理我的日常,不管是做项目或者是写文章、做视频等等。
「逍遥漫游,即时创作」是我最近在合桃派的一次直播,也是我使用 Roam Research 两年多的经验总结,分享的内容会比较详细啦,也可以推荐大家去看看。另外在 B 站上面,我有做过六十多个视频,也是一个不断输出不断学习的一个过程。
在高速摄影机出现之后,我们就相当于有了一种新的认知元素。Michael Nielsen 物理学家在 Thought as a Technology 这篇文章提到 Tools for Thought 就是思维层面的工具,当我们拥有了一个新的认知元素,就可以在更低维度或者说在不同的维度去观察,那些以前我们觉得非常习以为常的一些元素,或者是概念、事物。
唐·诺曼,全球最具影响力的设计师,《设计心理学》的作者,苹果的前用户体验架构师,在他的《Things That Make Us Smart 让我们变聪明的事情: 在机器时代捍卫人类属性》一书中提到:「人们高估了独立思考的能力。 没有外部帮助,记忆、思维和推理都会受到限制… …真正的力量来自于设计能够提高认知能力的外部辅助设备。」
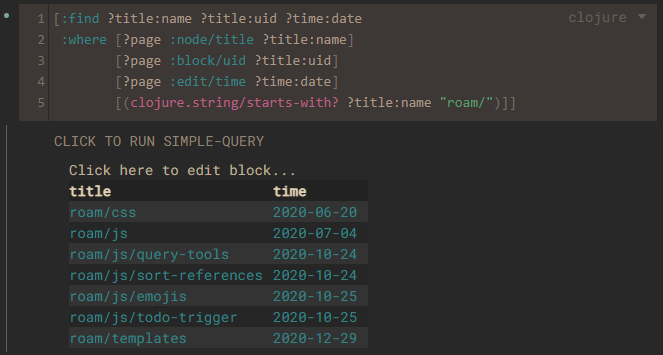
1. 页引用 [[]],“时空隧道”
Roam Research 的第一个概念就是页引用,大家接触双向链接之后最常见的双中括号的符号就是页引用。
其实,「人、事、果」就是可以把人、事情和结果全部都链接起来,就很像一些在线协同工具,像飞书、钉钉、Microsoft Teams 都在尝试将组织、文档和目标链接起来,但可能都没有做到真正的双向链接。这样的话,公司在评估项目结果的时候,就可以看到有哪些人参与进来了,然后有哪些事情(“一事一文档”)被完成了,并且这这些事情所对应的人和目标其实也是非常清晰的。
我平常会积累一些模板,每当我需要做一个决定,第一件事情应该去扩充自己的可选项。面对选择,其实不只有 A 或者 B 这两个选项,而是有更多可能的选项。比如说当我思考直播分享要不要开摄像头,原本的答案可能只有「开」和「不开」这两个选项,但其实我还可以思考一下,摄像头是不是买好一点?或者我可以开美颜?甚至是换上正式一点的衣服?
而观众不会永远被动,早晚都要反击。其实办法也很简单,就是要在你消费之前去创作,Create Before You Consume。我特别期待于 Web 3.0 的到来,所以我们应该尽可能的 Publish More,就像我在读文章的时候,我也会想:当我看了这篇文章准备消费下一篇文章的时候,我对当前内容有没有什么评价呢?
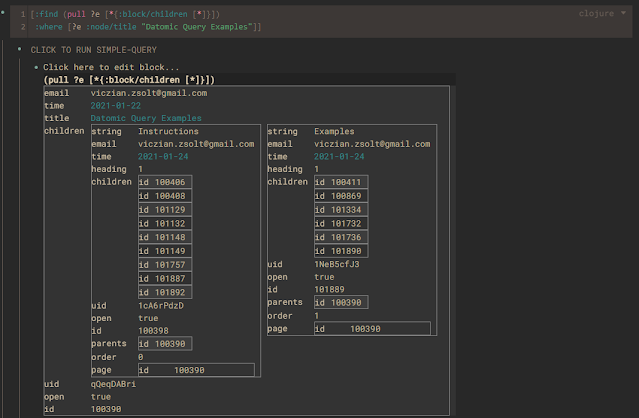
就像在 Roam Research 里面,我最喜欢的是它的 block reference 块引用,比如说我可以通过 (()) 来找到任意可以引用的内容,然后还直接把我需要引用的内容快速地粘过来,然后打上我想要的标签。
就像 Tim Ferriss 提到,我们在 2022 这个新年之际,不要去做那么多的新年愿望,雄心勃勃地觉得自己新的一年会有新的改变。但其实这么多年过去了,今年是什么样,去年是什么样,有多大差别难道你自己还不清楚吗?所以说大家应该多做 Past Year Reviews(PYR)也就是过去一年的回顾,少做 New Year Resolutions 新年愿望。
—— 唐·诺曼,全球最具影响力的设计师,《设计心理学》的作者,苹果的前用户体验架构师《Things That Make Us Smart 让我们变聪明的科技: 在机器时代捍卫人类属性》
继 Obsidian 之后,Roam Research 是更好的一款能帮我提高认知能力的外部辅助设备,也可以称之为“第二大脑”,我会谈一谈为什么会在接触 Obsidian 之后再次选择 Roam Research 的背后原因。
最重要的原因在于,Roam Research 可以将文本的颗粒度拆分得更细。组块(block)是认知科学上的一个常用概念,而 Roam 每一个文本组块(Block)正是这个概念的具象化。我们都知道,当你记忆一个手机号码时,比如,13912345678,很难直接记住。当你把它拆成139-1234-5678这样三个组块时,就更容易记忆。
这会让你更关注已完成而非未完成。现阶段所有的任务管理工具都是围绕未完成来做的,对于已完成事项的利用价值远远不够。而在 Roam Research 中所记下的间隙日记,你做事情是为了获取洞见,而不仅仅只是把事情做完。
哪怕是 Review,之前的我也总是在回顾那些未完成的项。从而导致自己很焦虑,与此同时我们也总是在自责,回避型人格,中国的传统家庭教育少了太多的鼓励。其实间歇日记或感恩日记,都是让自己重新关注那些已完成的东西,比如 Things 3 里面的 log 日志页面或 Flomo 的热力图 都让自己知道自己有多棒。持续积累素材到自己的数字花园,以此为动力,心情愉悦,马达轰鸣。
3.3 Roam Research 乃写作的“最佳后厨 ”
Roam Research 是文本类知识创作的最佳后厨,大纲式的编辑体验极佳,无往而不利。理想情况下,我认真筛选/整理/管理 Daily Notes 里面的内容放到卡片盒,精心编辑我的收藏内容,其目的都是为了在 Roam Research 里面方便调用,配合 Roam 最佳后厨专心负责拼装。或许,相比之下,我的 DEVONthink 更像是地下室,或者楼阁,一般不会去找,但如果要翻找,也能方便地搜索。
我的 📝 Zettelkasten 卡片盒
那么接下来我会演示一下如何在 Roam Research 的具体页面中进行输出,只有知识创造才能发挥 Roam Research 的最佳价值,比如以本文的创作过程为例,我会创建一个 [[P/Roam Research 101]] 页面,进入某一个页面再进行写作,可以称之为项目笔记(Project Notes)。
在 Roam Research 里面左侧称之为「主页面」,而「侧边栏」则可以打开多个其他页面,由此进入到第一阶段,在主页面快速记录下自己能够想到的任何相关内容,然后在侧边栏 Sidebar 视图快速打开所需要的所有素材。
将所有素材摆在一起之后,第二阶段便可以通过 /diagram 打开 Roam Research 内置的Diagram视图对内容进行排序处理,以线性的方式顺序排列组合出文章的大纲。
通过 Diagram 视图产出大纲
最后的第三阶段,则是通过树状的句法,用线性的文字展开,即通过逻辑语句完整地描述想要表达的内容。至此,Roam Research 帮助我完成了整个写作流程,快写慢改,一篇文章最终新鲜出炉。
「写作之难,在于将网状的思想,通过树状的句法,用线性的文字展开」—— 史蒂芬· 平克
这就是我对于一篇文章的创作流程的理解,即厨房的隐喻,Mise en place,在法语中的意思是指「在烹饪前,将所有的材料准备好,摆放在一个地方,让你一眼能看到」。这样做不仅仅是告诉观众需要哪些食材,更重要的是帮助厨师更好更从容地烹饪。厨房是知识型工作的终极隐喻,因为厨师必须在紧张的时间压力下,将精雕细琢的产品提供给苛刻的观众。
四、结语:知识创造而不是知识管理
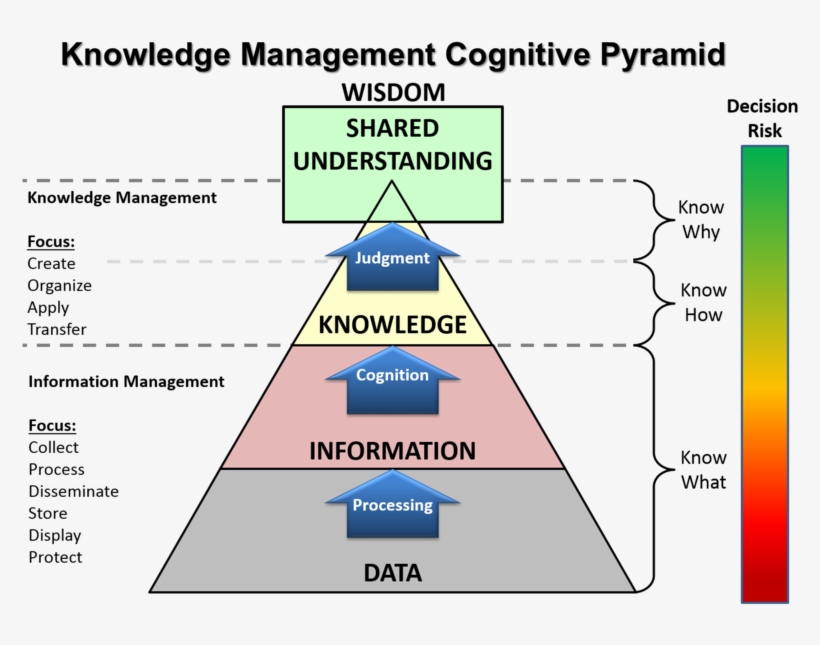
4.1 我的 Roam Research 使用体验隐喻之 DIKIWI 模型
我在少数派[Matrix 圆桌
网状结构笔记工具是一阵风吗?](https://sspai.com/post/61886)中就提到了这段 Roam Research 的使用体验隐喻:
有几个方法可以绕过这种不可变性。其中之一是通过使用 atoms。 atom 的工作原理我就不深究了(顺便说一句,就算我想解释也解释不清楚),Atom 就是对一个值的引用。使用 swap!reset!可以把这个引用改成一个新的值。在clojure.core/swap!中,你可以在给 Atom 分配新的值之前访问它的前一个值,在clojure.core/reset!中,你只需给 Atom 分配一个新的值,而不用去管它的前一个值。